How Twitter Could Fix Creator Monetization

Now when you open X, it's mostly you being triggered by someone or most likely seeing low quality content. And what's worrying is, the tweets going viral are rarely the most thoughtful or well written, because going viral now requires engineering a reaction.
This is not a coincidence. Monetization on X wasn't built to account for these engagement hacks.
The Core Problem
X pays creators based on impressions. On the surface, that sounds fair. More people saw your tweet, so you earn more. The problem is in how impressions actually get generated. The fastest way to drive impressions is to drive replies and quote tweets, because every reply and quote pushes the original back into more feeds. Think of replies and quotes as the fuel and impressions are what the fuel produces.
And here is where it breaks. People reply and quote for two very different reasons. They engage because they agree, or they are upset. However, the system treats both the same way. A tweet that teaches you something useful and a tweet that insults half the country can earn similar amounts of money, as long as the arguments keep happening in the replies.
So creators figure this out and lean in. Bad takes get rewarded. The feed gets worse. Everyone loses except the creators farming reactions.
The fix is not to stop paying creators. The fix is to change what we are paying them for.
The Principle
Pay creators for the value they add to the platform, not just the noise they generate.
A working monetization system should reward the creator who writes a thread that a thousand people bookmark for later. It should not reward the creator whose post got a thousand angry replies calling them stupid.
The rest of this article is how you would actually build that. Every number I use is a design choice. They could be moved. But they are concrete enough to argue about, which is the point.
Not All Engagements Are Equal
Bookmarks, quotes, replies, retweets, and likes mean very different things. The system should weight them accordingly.

The weights come from two things. How much effort each action takes, and what each action tells you about how the person felt. A bookmark means come back to this. A like could mean anything from I love this to my thumb slipped. That gap is what the weights capture.
Bookmarks earn the highest weight, with one honest caveat
Bookmarks at S tier is the biggest weight in the whole system, so it deserves a proper defense.
When someone bookmarks a tweet, they are saying this is worth coming back to. They want to save it. They want to reference it later. That is close to pure signal that the content has value.
But there is one caveat. Not every bookmark is appreciation. Sometimes people bookmark to keep receipts. A rival fan saves a bold football prediction to use as ammunition when it fails. People do this with political takes, tech predictions, anything someone might want to throw back in a creator's face later.
So is the bookmark signal broken by this? No, and here is why.
A receipt bookmark is still a signal of something. The person thought the tweet was memorable enough to save. They are not saving random noise. So even the "negative" bookmark tells you the tweet had weight.
The bigger reason is that receipt bookmarks are a small fraction of total bookmarks on any given tweet. If a prediction goes viral enough to attract receipt-keepers, most of the people seeing it are also bookmarking for normal reasons.
And the most important reason is that the other checks in the system catch creators who farm receipt bookmarks. Their replies turn negative over time. Their like to dislike ratio sours. The sentiment check we are about to get to will discount their engagement. The bookmark count looks good but everything around it collapses.
This is actually the core design principle of the whole system. No single check has to be perfect. Each check catches some failures, and the failures that slip through one usually get caught by another. That is why bookmarks can stay at S tier even though the signal is not pure.
Quotes and replies are their own tweets
Quotes sit at A tier and replies at B tier. The reason quotes rank higher is not really about effort. It is about distribution.
A quote tweet is a small piece of independent content. It shows up on the quoter's timeline. Their followers see it. It can go viral on its own. A reply lives in the thread of the original and has less independent reach.
This framing matters because it sets up the next question. If a quote tweet is really its own tweet, then whose engagement is it? We will come back to this.
Also worth flagging now. A quote tweet from a fan and a hater look identical in the data. They both count as one quote. The sentiment check will fix this by scaling the value of quotes and replies based on how the original was received.
Retweets, then likes
Retweets are C tier, weight 2. One tap, but it puts the retweeter's reputation on the line. Weaker than a quote but stronger than a like.
Likes are D tier, weight 1. People like things they barely read. The bar is so low that it does not tell you much. But likes still matter at scale, so they get a small weight.
When Your Reply Goes Viral, Who Gets Paid?
Imagine someone tweets a hot take. An influencer quote tweets it with their own take, and the quote tweet goes viral. Who earned that money?
In a simple system that credits all engagement back to the original, the original creator gets paid for a viral tweet they did not really make viral. The influencer did the work. The influencer's audience showed up. The influencer's framing is what people are reacting to. The original was just the spark.
That is not fair. Here is how I would split it.
The viral quote earns for its own creator
A quote tweet is really its own tweet. It has its own distribution. Its own engagement. It should earn for the person who made it. Same logic for a reply that takes off.
When your quote or reply picks up engagement, all that engagement counts toward you. You run through the same formula as any other tweet, because your quote is a tweet.
The original gets a 10% finder's fee
The original creator did contribute something. They posted the thing that the viral quote was reacting to. So they should get a small share.
I would set the finder's fee at a flat 10%. The quote creator keeps 90%. Small enough that the quote creator is clearly the one getting paid. Meaningful enough that original creators still get rewarded when their posts spark conversations.
A flat rate is deliberate. It could scale with quality of the original, but that adds complexity for not much gain. A flat 10% is easy to explain and implement. It also helps small creators specifically. A small account that posts something thoughtful and sparks a viral take from a bigger account gets a real share of that, instead of losing out completely.
The fee depends on the category of the original
Without this, the finder's fee creates a side door for rage baiters.
Imagine someone who posts deliberately terrible takes designed to attract viral takes from others. The person quoting them does the work, but the rage baiter still gets 10% of every viral take on them. Rage bait becomes profitable through a back door.
The fix is to gate the finder's fee by category.

This closes the rage bait side door cleanly. Rage baiters still earn from their own direct engagement, but nothing from viral takes on them. Original creators get to participate in the upside of conversations they sparked. That feels right.
The Sentiment Check
Before we get to the sentiment check, an honest assumption. I am assuming X could add a dislike or downvote feature, even if just for the monetization algorithm and not publicly visible. Without some form of negative signal, the system cannot tell the difference between loved content and content that is just loud.
Right now, the only negative signals on the platform are flags and reports. Those are too extreme. People only flag tweets that are truly bad. They do not flag tweets that are just low quality or annoying. So most low quality content slips through.
A dislike button would fix this. If that is not on the table, you could approximate the signal from hide rates, mute rates, and negative reply patterns. A dislike button is cleaner.
How the check works
The sentiment check looks at the like to dislike ratio on the original tweet. If broadly liked, its quotes and replies count as positive engagement. If broadly disliked, those quotes and replies are probably people taking shots at it.
The score gets applied as a multiplier to the weight of quotes and replies.
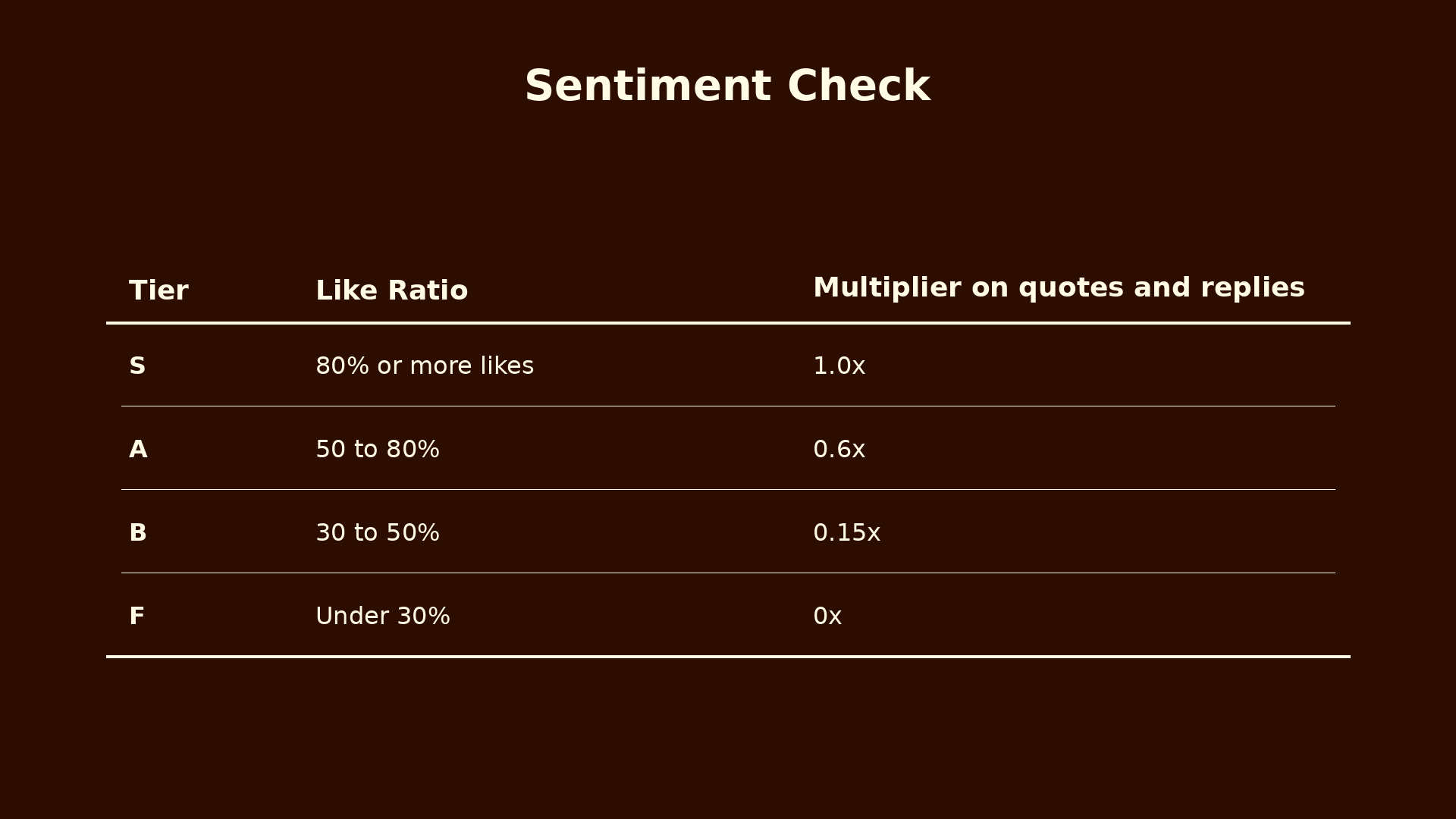
The jumps between tiers are deliberately harsh. If someone slips from 81% to 79% likes, they lose 40% of their multiplier. That sounds brutal, but it is on purpose. A smooth gradient invites gaming. Hard cliffs mean the incentive is to stay clearly in the well liked zone, not to hover near the edge.
This is the single most important fix in the whole system. A ratioed tweet can pull a million angry replies and they will count for almost nothing. The tweet still drove impressions, but the engagement that drove those impressions does not pay out.
Bookmarks and retweets are not discounted by sentiment, because they are unambiguous positive actions. Nobody bookmarks a tweet they hate. Retweets are endorsements. Only quotes and replies get scaled.
Content Categories
Not all content deserves to earn the same. The system should classify tweets and apply a multiplier.
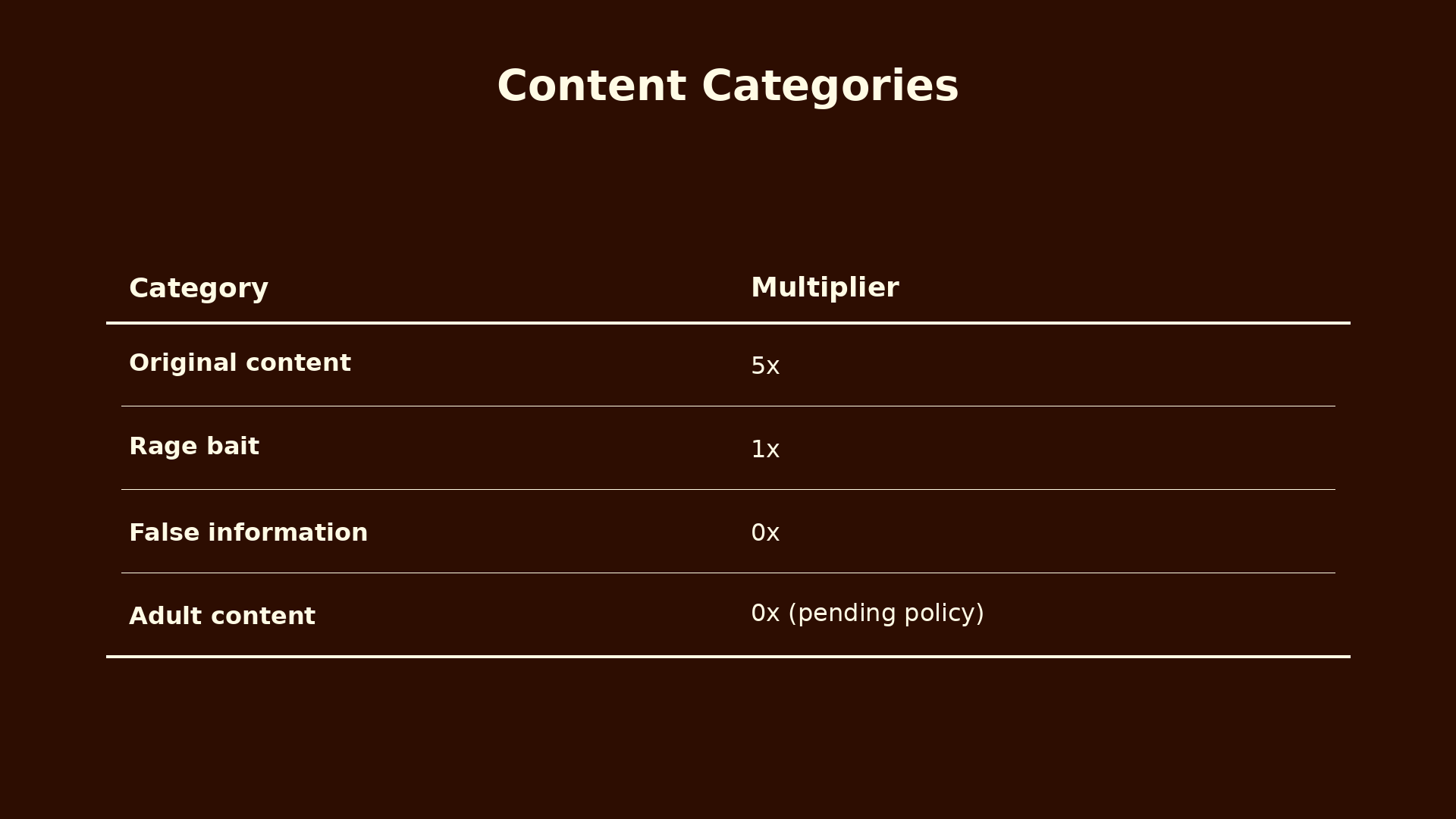
The 5x gap between original and rage bait is the most important design decision here. A 2x or 3x gap would not be enough. Creators would still rationally choose rage bait for the engagement volume. At 5x, original content earns more even when rage bait gets more raw engagement.
False information at hard zero, not just a reduction, is also deliberate. A multiplier of 0.1 would still reward viral misinformation proportionally to its reach. That is the wrong incentive at any rate above zero. Either the platform pays for truthful content or it does not. There is no middle ground.
How you would actually classify tweets
This is the hardest part of the whole system. The math is easy once you know the category. Figuring out the category is not easy.
You cannot do it manually. Millions of tweets go up every day. You need automated systems trained on thousands of examples, with humans for edge cases and appeals. YouTube has been doing this for almost two decades and still gets it wrong regularly. Any system X builds will get it wrong sometimes. That is fine, as long as there is an appeals process and the system keeps learning.
A perfect classifier is not required. A reasonable classifier combined with all the other checks produces much better outcomes than the current system does.
Audience Quality and Flags
It does not just matter how many people engage with your tweet. It matters who they are.
Ten thousand likes from real active users is not the same as ten thousand likes from bots. Or from the same fifty accounts who always engage with each other, which is what we call an engagement hive.
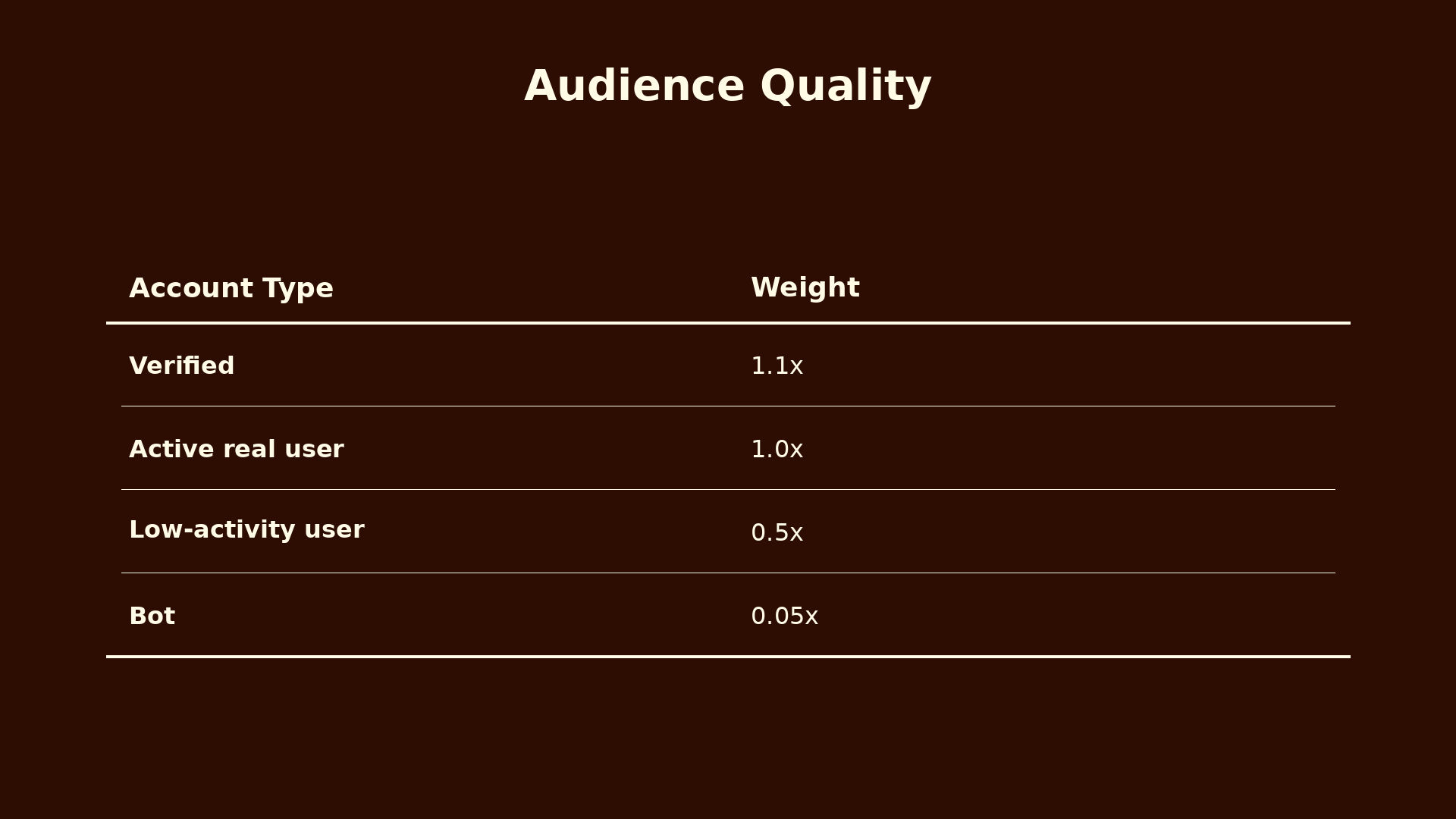
The verified weighting is the one that might surprise people. Before anyone could pay for a checkmark, verified meant notability. Now that it is a subscription, it barely indicates anything beyond willingness to pay. A small bonus at 1.1x is fine, but anything higher would let paid accounts dominate the audience score unfairly.
Engagement hives
An engagement hive is a coordinated group of creators who agree to boost each other's content. They all like, reply to, and quote each other's posts within minutes of publication. This tricks the algorithm into thinking the content is going viral, which causes it to show the content to more people, which often causes real engagement on top of the fake.
Hives are a problem because they look like real engagement. The accounts are real. The replies are real human writing. It is just humans gaming the system together.
Beyond the weighted averages, there is a hard penalty when the bot percentage on a tweet is unusually high.

The 20% threshold acknowledges that some bot activity is normal. Below that it is noise. Above that it starts to look like coordination. Above 40% there is no innocent explanation.
This does not fully close the loophole for human-only hives, where real people coordinate. The bot penalty does not catch those because the accounts are not bots. The way to catch human hives is the follower graph. If the same fifty accounts keep engaging with each other's tweets and they all follow each other, that is a hive signature. A healthy viral tweet has engagement from a diverse set of accounts who do not all know each other. Building the graph check is more engineering, but solvable.
Flags
When users report a tweet, that is a strong signal something is wrong. The system should take flags seriously. The rule is that a small percentage of flags should create an outsized penalty, because even a 1% flag rate is meaningful. One percent of a million engagements is ten thousand people saying this is wrong.
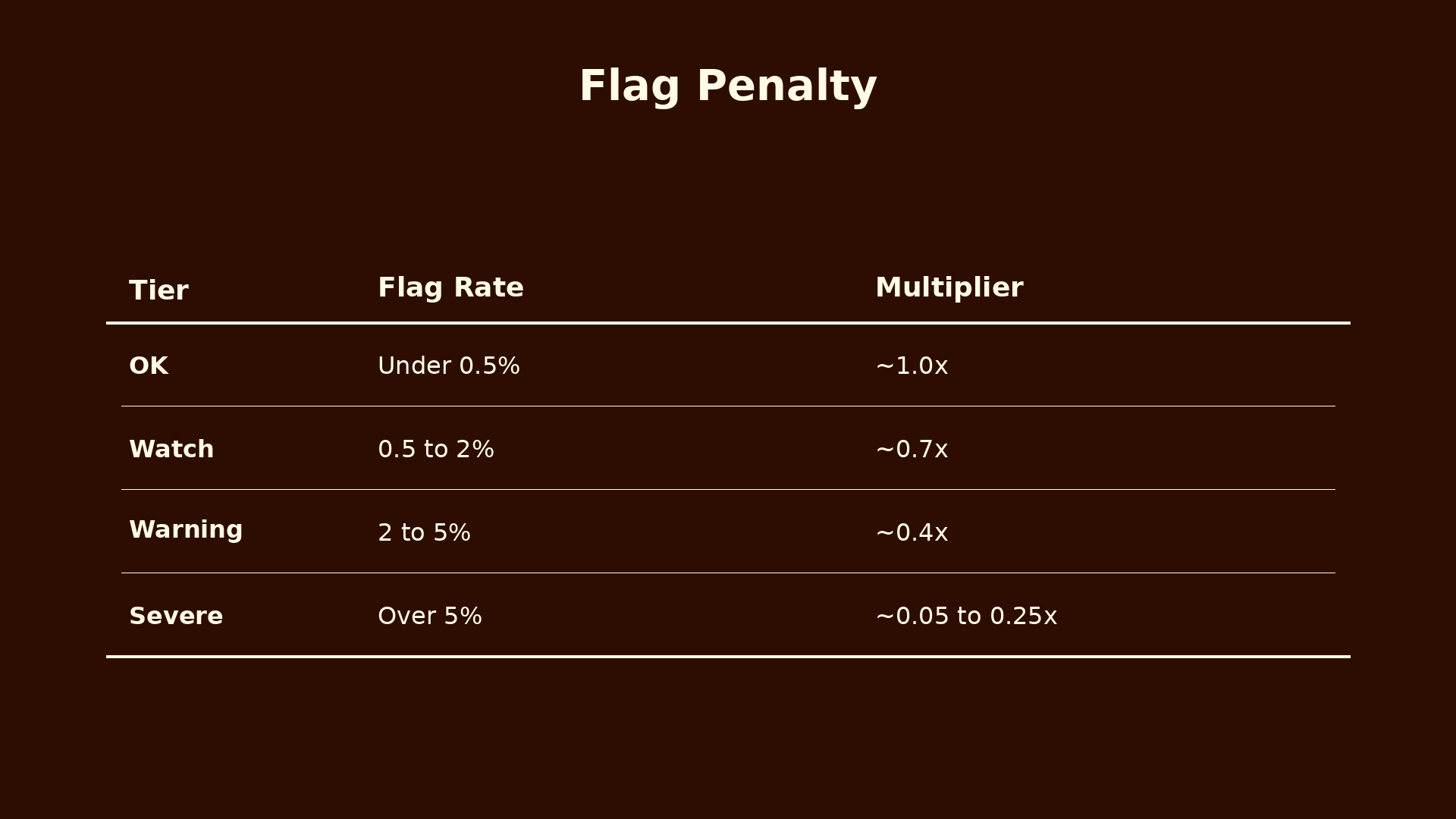
Look at the bottom row of that table. The multiplier never drops below 0.05x. That 5% floor matters. Without it, a coordinated group could mass-report a creator's tweet and zero out their earnings entirely. Reporting becomes a weapon. The floor means even an extremely high flag rate still leaves the creator with some earnings to fight over, which protects against report bombing while still meaningfully punishing genuinely flagged content.
The Fairness Problem
Ad rates are not equal around the world. Advertisers pay more to reach users in North America and Europe than they do to reach users in Africa or South Asia. This is because of differences in purchasing power and how much ad budget gets spent in each region.
What this means is that a creator in Ghana and a creator in New York can produce the exact same tweet, reach the same number of people, get the same engagement. The Ghana creator still earns about one fifth as much, purely because of where their audience lives.
This is wrong. Or at least, a global platform should have an opinion about it.
The simplest fix is a minimum ad rate floor for lower CPM regions. North America and Europe stay at their full market rates, because that is where the actual ad money is. But the floor lifts creators in lower rate regions so they are not structurally punished for geography.
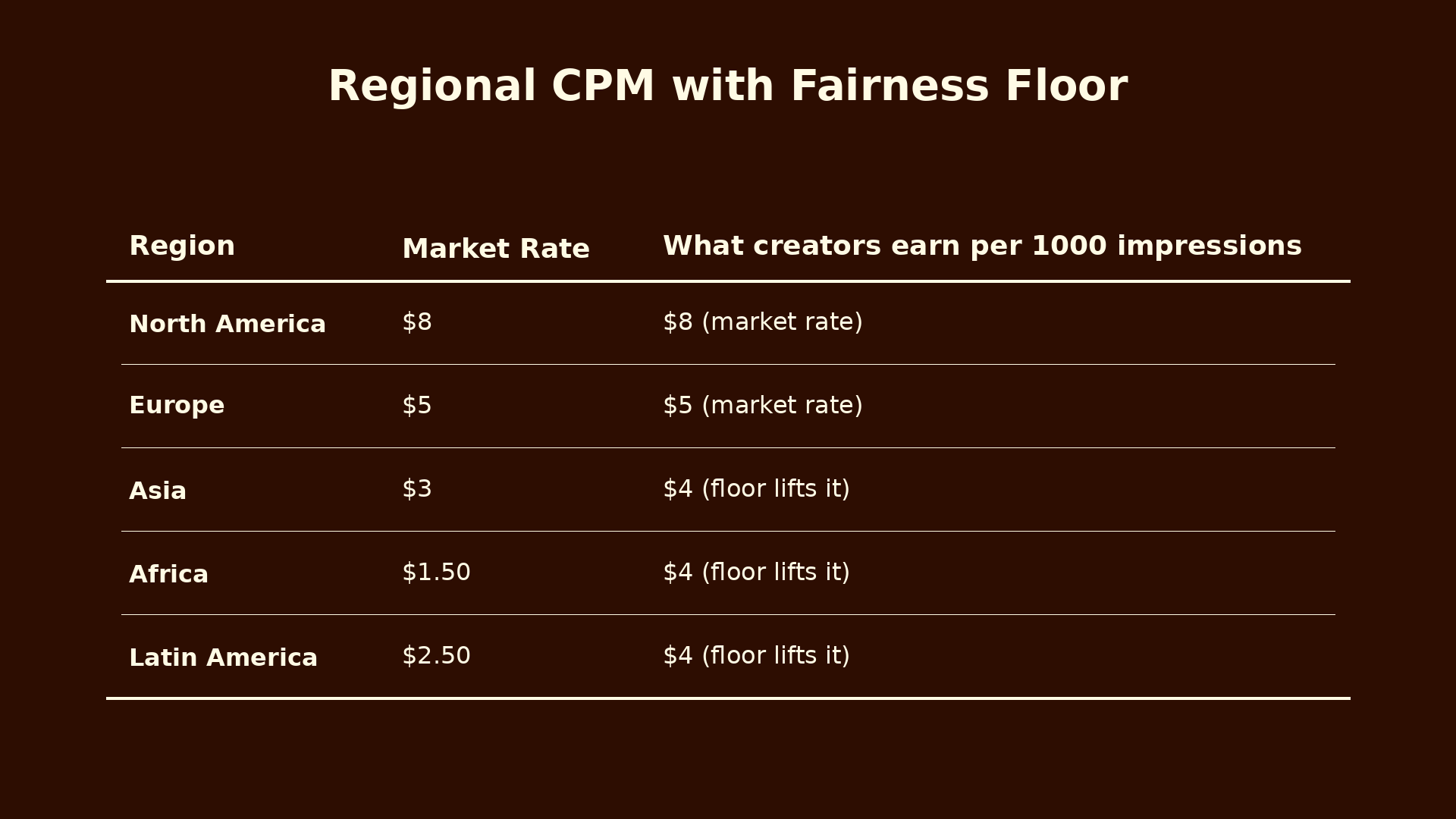
This is a subsidy. The platform uses premium ad revenue from wealthy markets to raise the floor for everyone else. That is fine. A platform with a global user base should act like one.
Setting the floor at $4 is a judgment call. Too low and the subsidy does not meaningfully help. Too high and the platform loses too much on every impression in those regions. Half the top rate feels reasonable.
The alternative is letting the market set the rates purely. What that produces over time is global creators quietly giving up on the platform because the economics do not work for them. Platforms that have a global user base but pay like a local platform lose their global creators to platforms that pay more fairly.
How It All Fits Together
Every tweet starts with a baseline. Impressions times CPM divided by 1000. That is the most the tweet could possibly earn.
Then we apply a series of checks that can only reduce earnings, never inflate them.
- The engagement quality check. Bookmarks and quotes count more than passive likes.
- The sentiment check. A ratioed tweet under 30% likes gets its quotes and replies zeroed out.
- The audience quality check. Bot heavy engagement gets penalized at 0.3x or 0.1x.
- The flag check. Even small flag rates produce real penalties, scaling to a 0.05x floor.
- The category check. Original earns 5x. Rage bait 1x. False info zero.
Separate from all that, there is the finder's fee. If your tweet sparks a viral quote or reply, you get 10% of what the quote creator earns, but only if your original was classified as original content.
A tweet that passes all the checks earns close to its full potential. A tweet that fails one or two earns a fraction. A tweet that fails most of them earns almost nothing. A tweet flagged as false information earns exactly zero, no matter how viral.
That is the shape. Pay for value, not for noise.
What This Looks Like in Practice
To make this concrete, let me walk through two tweets from start to finish. Same reach, same region, same CPM. Very different content.
Both tweets reach 500,000 impressions in North America, where the CPM is $8 per 1000 impressions. So each tweet generates $4,000 in baseline ad revenue (500,000 divided by 1,000, times $8). That is the starting pool before any checks reduce it.
Tweet A, a quality original thread
The stats:
- 10,000 likes, 500 dislikes
- 2,000 bookmarks, 800 quotes, 1,500 replies, 3,000 retweets
- 50 flags total
- Engagers are 15% verified, 80% active real users, 5% bots
- Classified as original content
Step 1, sentiment check
Like ratio: 10,000 ÷ (10,000 + 500) = 95.2% → S tier → LDR = 1.0
Step 2, engagement score
This sums every engagement type by its weight. Quotes and replies get scaled by the LDR. Bookmarks, retweets, and likes do not.
BES = (2,000 × 5) + (800 × 4 × 1.0) + (1,500 × 3 × 1.0) + (3,000 × 2) + (10,000 × 1) = 33,700
Step 3, engagement rate
This compares the engagement score to impressions. Catches tweets boosted by the algorithm but ignored by people.
Engagement rate: 33,700 ÷ 500,000 = 6.7% → A tier → ERM = 1.5
Step 4, audience quality
AQS = (0.15 × 1.1) + (0.80 × 1.0) + (0.05 × 0.05) = 0.97
Step 5, flag penalty
Flag ratio: 50 ÷ 17,800 = 0.28% → OK tier → FP ≈ 0.84
Step 6, quality multiplier
QM = LDR × AQS × FP = 1.0 × 0.97 × 0.84 = 0.81
Step 7, category multiplier
Original gets the full 5x.
CCM = 5
Final
Earnings = $4,000 × 1.5 × 0.81 × 5 = $24,300
Tweet A earns about $24,300. Quality content, positive sentiment, real engagers, minimal flags, strong engagement rate. The system rewards it.
Tweet B, a rage bait post
Same walkthrough, different content:
- 8,000 likes, 12,000 dislikes
- 200 bookmarks, 5,000 quotes, 15,000 replies, 2,000 retweets (huge volume of quotes and replies because the tweet made people angry)
- 3,000 flags
- Same engager mix
- Classified as rage bait
Step 1, sentiment check
This is where it starts to break.
Like ratio: 8,000 ÷ 20,000 = 40% → B tier → LDR = 0.15
The LDR of 0.15 is what kills this tweet. The sentiment multiplier on its quotes and replies drops to almost zero.
Step 2, engagement score
Watch the volume get crushed.
BES = (200 × 5) + (5,000 × 4 × 0.15) + (15,000 × 3 × 0.15) + (2,000 × 2) + (8,000 × 1) = 22,750
Without sentiment scaling, raw BES would have been near 60,000. The sentiment check cut it to 22,750.
Step 3, engagement rate
ER: 22,750 ÷ 500,000 = 4.5% → B tier → ERM = 1.0
Step 4, audience quality
Same as Tweet A.
AQS = 0.97
Step 5, flag penalty
Big hit here.
Flag ratio: 3,000 ÷ 42,200 = 7.1% → Severe tier → FP ≈ 0.20
A 7% flag rate is roughly one in fourteen engagers reporting the tweet. The penalty cuts the quality score by 80%.
Step 6, quality multiplier
QM = 0.15 × 0.97 × 0.20 = 0.03
Step 7, category multiplier
Rage bait gets 1x, not 5x.
CCM = 1
Final
Earnings = $4,000 × 1.0 × 0.03 × 1 = $116
Tweet B earns about $116. Roughly one two-hundredth of Tweet A, despite having more than double the raw engagement volume.
Three separate multipliers collapsed the earnings. The sentiment check dropped the quality score through LDR. The flag penalty dropped it further. The category multiplier capped the ceiling at 1x. No single check did it alone. They stacked.
And if Tweet B went viral from takes on it
One more wrinkle. Imagine Tweet B got its huge reach because an influencer quote tweeted it and went viral. In a simple system, Tweet B would have captured some of that value through its quote count.
Under the rules above, the viral quote earns for the influencer, not for Tweet B's creator. And because Tweet B is classified as rage bait, the 10% finder's fee does not apply. So Tweet B's creator earns exactly $116 from direct engagement and zero from any viral takes on them happening elsewhere.
Meanwhile the influencer earns based on their quote tweet's performance, run through the full formula like any other tweet.
The math is not the point. The point is the system makes quality obviously more profitable than rage. Creators trying to make a living follow the money. The money flows toward content the platform should actually want.
I also built a calculator you can play with to see how everything comes together. Try it here.
Some Assumptions Worth Naming
Good product thinking is honest about what it is assuming. Here is what this whole system rests on.
Assumption one: X wants a better feed. This only makes sense if the platform actually wants to reduce rage bait and reward quality. If the goal is purely short term engagement, the current system is fine. I am assuming X wants a better feed because advertisers want brand safety, competitors are peeling off quality creators, and long term health depends on being a place people actually enjoy using. But this is an assumption.
Assumption two: Creators respond to incentives. Most creators are trying to make a living. If you change what you pay for, they will change what they make. Some are rage farmers on purpose, and they will not change. But most will follow the money.
Assumption three: Classification can be good enough. Not perfect. Just good enough that the system is better than the current one. This is where most of the implementation risk sits.
Assumption four: A dislike signal is achievable. Either an actual dislike button or a good proxy from hide rates, mute rates, and reply sentiment. Without some form of negative signal, the sentiment check cannot work.
Why This Matters
The feeds we use shape how millions of people see the world. When those feeds reward outrage, the world looks more outraged than it actually is. When they reward thoughtfulness, more people write carefully, fact check themselves, bookmark instead of keeping receipts. That doesn't mean a little banter is bad.
Every number in this article is a design choice. The 5x for original content, the bookmark weight, the $4 fairness floor, the 80% sentiment threshold. All of them could be moved. What matters is the shape of the system. Every check can only reduce earnings, never inflate them. No single check has to be perfect because the checks stack. Content gets rewarded for being valuable, not for being loud. Creators in low CPM regions are not punished for geography. And the whole thing is transparent enough that creators can see why they earned what they earned.
None of this requires a revolution. It just requires changing what we pay for.
The current system pays for reactions. A better system would pay for value. The difference is the difference between a feed that feels like a fight and one that feels like a place worth spending time in.
In the next piece I want to apply this same thinking to the media side, because news organizations and journalists face their own version of this problem.